Apple Silicon M3 Pro competes with Nvidia RTX 4090 GPU in AI benchmark [u]

In a recent test of Apple's MLX machine learning framework, a benchmark shows how the new Apple Silicon Macs compete with Nvidia's RTX 4090.
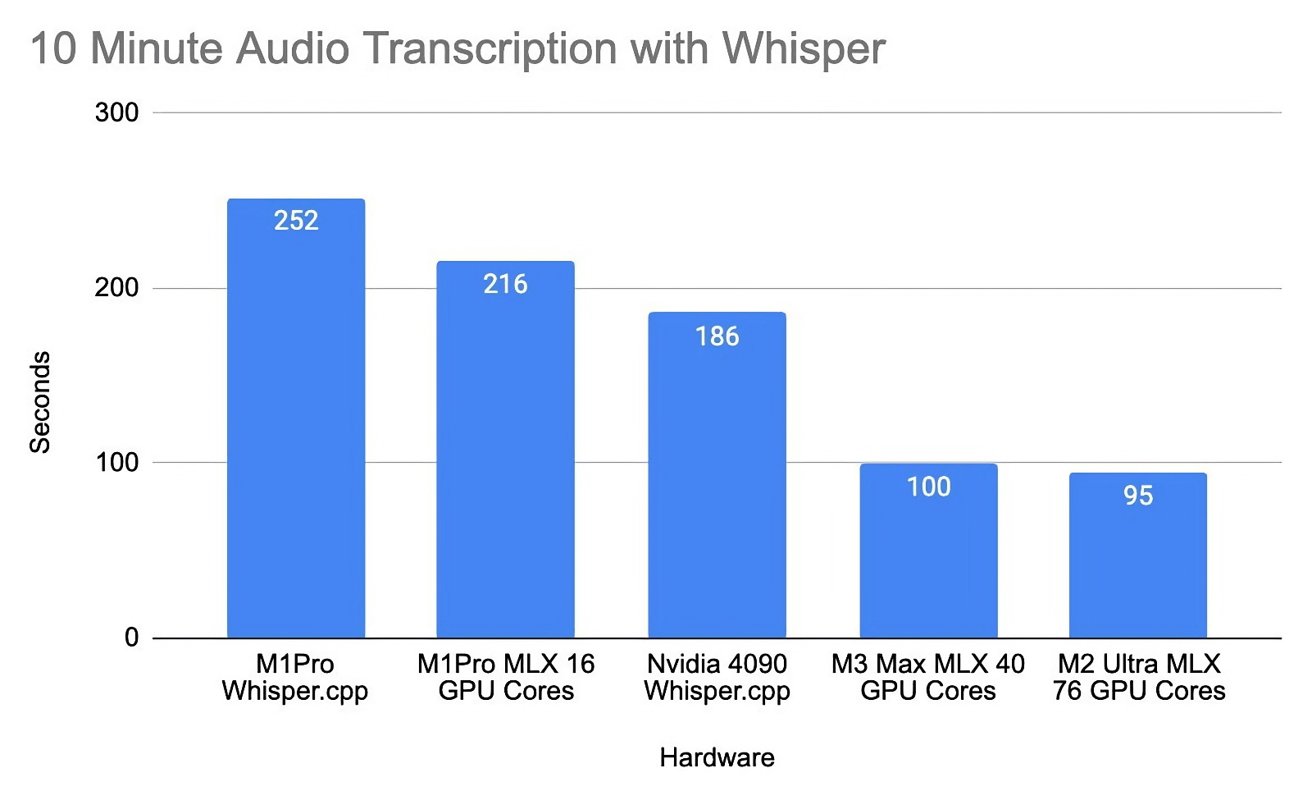
Whisper performance
Apple announced on December 6 the release of MLX, an open-source framework designed explicitly for Apple silicon. It's meant for AI developers to build upon, test, use, and enhance within their projects.
Developer Oliver Wehrens recently shared some benchmark results for the MLX framework on Apple's M1 Pro, M2, and M3 chips compared to Nvidia's RTX 4090 graphics card. It makes use of Whisper, OpenAI's speech recognition model.
Wehrens uses the Whisper model for transcribing speech and measures the time it takes to process a 10-minute audio file. Results show that the M1 Pro chip doesn't quite meet the Nvidia GPU's performance, taking 216 seconds to process the audio compared to the 4090's 186 seconds.
However, newer Apple chips have much better performance. For instance, a different person ran the same audio file on an M2 Ultra with 76 GPUs and an M3 Max featuring 40 GPUs and found that these chips transcribed the audio transcription in less time than the Nvidia GPU.
There is also a significant difference in power consumption between Apple's chips and Nvidia's offering. Specifically, when comparing the power usage of a PC with an Nvidia 4090 running versus its idle state, there's an increase of 242 watts.
In contrast, a MacBook with 16 M1 GPU cores shows a much smaller increase in power usage when active compared to its idle state, with a difference of just 38 watts.
The results highlight Apple's gains in AI and machine learning capabilities and could be the beginning of better capabilities for Apple products. With the MLX framework now open-source, it paves the way for broader application and innovation for developers.
Nvidia's 4090 GPU starts at $1,599 just for the card, without a PC. This is the same price as the M3 MacBook Pro from 2022 -- but prices increase rapidly for M3 Pro and M3 Max.
Using an optimized tool changed the results
An update to Wehrens' blog post changed the story. The M3 chips still performed well, but Nvidia cut its times by more than half when using appropriately optimized benchmark tools.
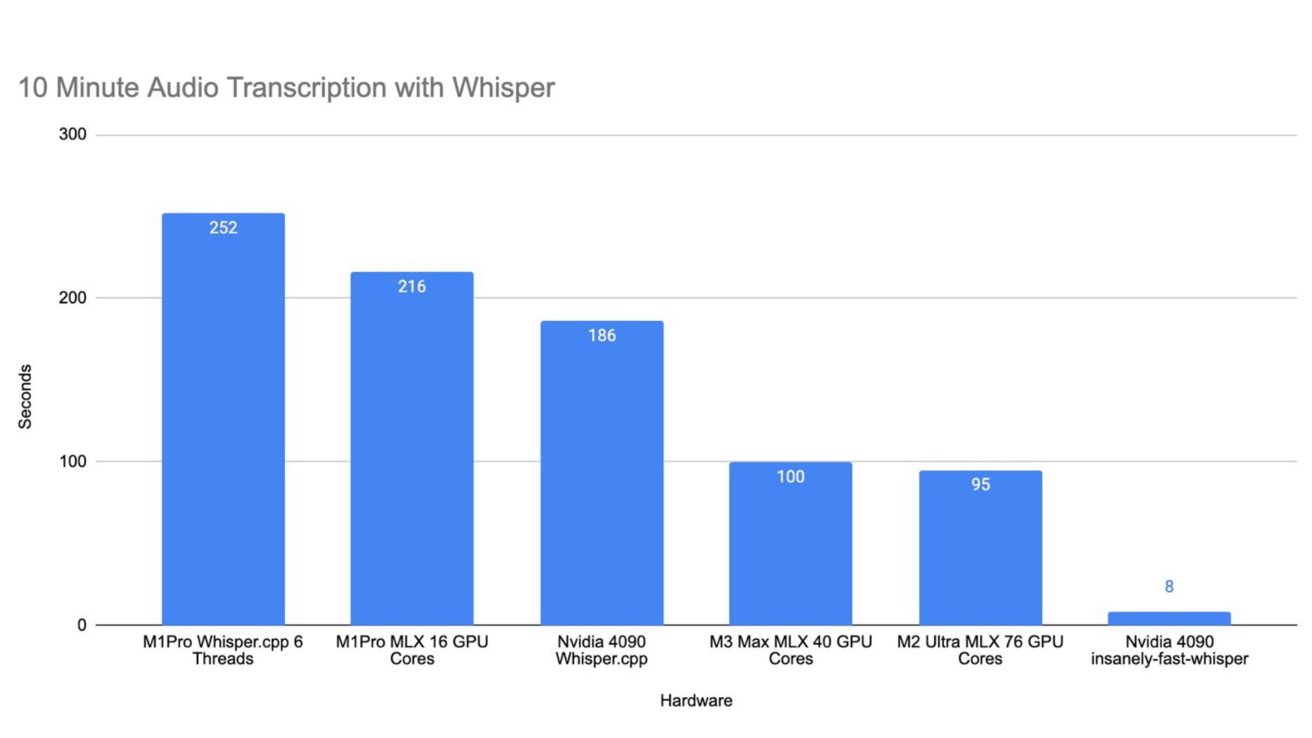
Updated Whisper performance
We're leaving the original story intact since it reflects how the non-optimized tool performed. However, Apple's processors still have a way to go to match Nvidia's when it comes to AI transcripts.
The most interesting factor to note is the difference in power consumption. That result didn't change -- Apple's chips performed well at a fraction of Nvidia's power draw.
With the new results from the Nvidia-optimized tool, the transcript is completed in 8 seconds. M1 Pro took 263 seconds, M2 Ultra took 95 seconds, and M3 Max took 100 seconds.
Apple's results were still impressive, given the power draw, but still didn't match Nvidia's. Apple Silicon still has some room to improve, but it's getting there.
Updated December 13, 6:50 p.m. ET: Original post used a non-optimized benchmark showing inaccurate results.
Read on AppleInsider
Comments
- allocate memory for matrix A, B, C on the GPU
- copy data from main memory A,B to A,B on the GPU
- call GPU to multiply and compute C
- Copy matrix C from GPU back to main memory
Comparison, while entertaining, is a bit misleading tho as it is comparing one architecture that is optimised for power efficiency against a plugged-in no holds barred GPU architecture. To say that Apple has a long way to go missed the point a bit.
The power consumption factor should be highlighted even more. The Apple benchmark is likely similar or the same if running plugged in or on battery. All-in the PC guts power consumption is likely 10x (or higher) of the M3 Max SoC. So if doing an amateur Watts x seconds calculation then the optimised Nvidia model is still faster than the MLX M3Max, but not by a whole lot at all.
RTX 4090 has a TDP of 450W. Laptop RTX 4090 is 175W (?). M3Max is far from this and Nvidia GPU power draw is not counting the PC CPU, RAM and other circuitry that resides in the M3 chip.
Now I wonder if there is any option to do a MLX version of the Nvidia optimised model. Perhaps there are many other tweaks in the model besides tuning it for Nvidia cards?
Also I wonder what performance numbers we would see if Apple would go on a ragga tip and do an M3 chip with a TDP of 450-700W. Maybe Apple has tried it and it didn't meet expectations. Chips be hard.
Hopefully M4 will be tripling down on genAI performance.
The headline says M3 Pro competes with....
The article doesn't list the performance of the M3 Pro
M3 Max yes
M1 Pro yes
M2 Ultra yes
And for those saying the Mac version isn't optimized, well, we can only comment on the data we have right now, which is, no optimized Mac version. When they optimized Mac version hits, then I can re-evaluate my remarks at that point in time. But for now, the crown is clearly on the head of the 4090, despite the massive increase in power consumption.
A single benchmark is useless in the field of AI, unless you are just doing that single task.
In the field of AI (in which I'm active) there are many tasks that demand different things from an SoC.
For example, in order to run a local LLM or image generation model, a lot of memory is needed (next to specs such as CPU).
A.I devs need to go all the way up to an M3 Max with 128gb of memory to run these models. With these specs 128gb really surpass it because it has direct access to it.
For most cases however, the 4090 definitely has the edge from a raw power p.o.v, not just because of the CUDA software<>hardware ecosystem
But then again, the M3 Max runs at 65 watts and the Nividia at 380 watts(!), and gets close enough not to be bothered by the slower performance.
https://github.com/Vaibhavs10/insanely-fast-whisper
The other test is sequential. It also says that optimal one runs on Mac.
It's not a fair comparison to put parallel software against sequential to show a 10x gain. That's like running After Effects sequentially on one machine and doing batch image processing on another. Of course it's going to be faster in parallel.
AMD and Nvidia have been squabbling about this recently:
https://www.tomshardware.com/news/nvidia-h100-is-2x-faster-than-amd-m1300x
That one mentions using FP8 calculations vs FP16. They say the result precision isn't compromised but still not a fair comparison.
If these benchmarks are going to be fair, there needs to be a standard for what is comparable. Compare same batch sizes, same compute units otherwise we're not talking about the capability of the hardware.
It's still valid to mention faster results regardless of the route used because in the end the result is what matters but all these manufacturers are working on the same base principles and software. It's about transistor count, clock speed, memory bandwidth etc. Nvidia 4090 is around 4x the raw hardware of M3 Max and M3 Max is on a more advanced node. The 4090 should be expected to be around 3-4x faster in most tests. M3 Max equivalent is the desktop 3070/laptop 4070, not the desktop 4090.
https://www.youtube.com/watch?v=jaM02mb6JFM
https://www.youtube.com/watch?v=5dhuxRF2c_w (Take a look at the power supply and plumbing) long term Apple is on the right path just takes a little longer, like replacing Intel.
A Extreme Mac Pro with 512 gig of UMA at 160 watts? Won't happen but the possibilities.......Apple as a vertical computer company are in a very good position.
No. You're not understanding it correctly. The author didn't do the math right. He has the total times. He has the power draw, but he only measured instantaneous power draw. He could have measured TOTAL power draw.
Using numbers from anantech, the M1 (not m2) Ultra Mac Studio drew 87 watts peak (if the the author of this article did the tests properly, we'd have better numbers), that's 87 watts * 95 secs = 8265 watts total.
for the 4090:
242 watts * 8 secs = 1936 watts total
meaning that even at that "inefficiency", the 4090 is using FOUR TIMES LESS ENERGY.
And if you insist on comparing your laptop to a desktop 4090, let's go back to the M1Pro chip, with MLX library, and why not? because the author does! his "38 wats" to the 4090's peak numbers:
38 watts * 216 secs = 8208 watts total.
Whoops. the 4090 still uses FOUR TIMES LESS ENERGY even than the M1Pro.
Absolutely - Watts (Volts x Amps) are unless without definition eg Watt/hours. Unfortunately this will happen, as journalism is usually the rehashing of other articles without the knowledge to know if they are correct, and then made worse by us and our uninformed comments here. If I wanted to write this article I would have to do the tests myself otherwise I would not have confidence that it was right.