tipoo
About
- Username
- tipoo
- Joined
- Visits
- 100
- Last Active
- Roles
- member
- Points
- 1,033
- Badges
- 1
- Posts
- 1,166
Reactions
-
Early benchmarks shows Samsung Galaxy S9 well behind iPhone X in processor performance
maestro64 said:it is now coming down to software optimization. pure processor power is not enough, unless the underlining code is optimize around the processor users will never see the performance. Even though the benchmarks try to work directly with the processor they can not they still have to interface with the operating system to execute code on the processor. The only way to eliminate the operating systems is to remove and replace it with the benchmark software which we know is not happening.
This is why Apple has the advantage and will always have the advantage. Google can not optimize their software to work with all the versions of processors.
Apple is shipping the widest ARM cores out there at 6-issue, everyone else is still playing with 4-issue. Nvidia tried 7 but their binary translation attempt made performance too weird.
Since core complexity goes up exponentially with width, Apple is also spending twice as much silicon per core, or at least were last year as the competition.
Point being it's not just some ambiguous whole banana optimization, Apple is shipping the most advanced ARM CPU cores in a phone period regardless of OS. For the Exynos Anandtech does mention it's a pre-release scheduler so some of it could be software, but even if things were perfectly optimized it would not be as good per clock as Apples wide core.









-
Apple Watch Series 4 in 40mm and 44mm sizes confirmed in sitemap leak
spheric said:
It looks like the bezels around the displays will be narrower (as with the later versions of iPhone), which would allow for larger displays (38 —> 40 mm and 42 —> 44 mm) without a change in the watch case design itself.jamiel said:Does that slight size increase mean existing bands won't fit either model?
The mm count is the lug to lug width, not display size.





-
New Magic Mouse said to fix everything that's been wrong with it for 15 years
The charging port location is about the least worst thing about it for me, I hope they redesign it from every atom up.
It feels weird having to hover a finger to properly right click, and there's no simultaneous left/right click which is a bit more esoteric but some apps can use.
The sensor and wireless stack are just abysmal now though, they never updated it in all the refreshes from the 11 year old sensor, it feels bad and skippy and once you use a good mouse you realize you weren't bad at aiming at fine targets, the mouse was. Check Rtings on the Magic Mouse 2 if you think that's dramatic.




-
MacBook Air 2018 Review: Apple's most popular Mac gets an impactful upgrade
ascii said:I am interested in whether a fast eGPU gets bottlenecked by the 7W processor. i.e. if you install the same game on the new MBA and on a MBP, and use the same eGPU, does the MBA get a lot less fps?
Sure it would, you can already see this with the 13 vs 15 CPUs, and the Pro 13 is a higher bar not to bottleneck the GPU with four cores and higher clocks. Depends on the task/title of course, but a 7W CPU will certainly bottleneck modern mid-high end GPUs a fair bit.
https://barefeats.com/macbook-pro-13in-2018-with-egpu.html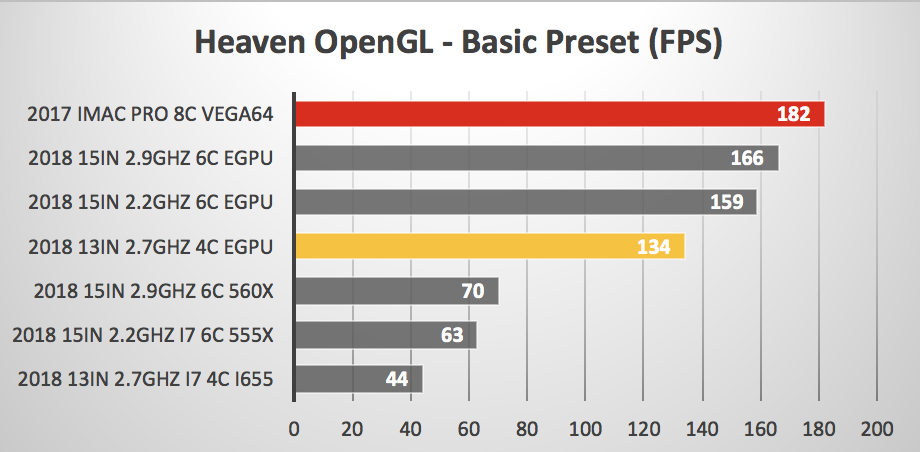



-
Data about Apple's AR headset screens has been leaked
If it's Micro OLED and 5000 nits, why would the contrast ratio only be 4000 to 1? They already boast 2 million to 1 on their phone OLEDs at under half the brightness



-
iPhone 15 Pro will have blistering performance, claims leaked benchmarks
At least it's more believable than the 4000 single core score Max Tech ran with lol.
At the higher end of an improvement this couuuld be believable with 3nm offering a big improvement over a few generations of 5nm, but this is also that timeframe of a lot of fake benchmarks, even if one shows up in the GB database sometimes it's later taken down as a fake and I don't see this one on there even. -
Face ID iPad, MacBook, Mac mini, MacBook Pro, 11-inch iPad Pro in Apple's 2018 product lin...
Mac Mini with the 8th gen ULV quads would be pretty sweet. Hopefully they revert from the stupid metal cage making upgrades harder for no reason, didn’t get smaller or even more powerful or anything, they just added it expressly to stop upgrades which was a piss off.





-
Apple to unveil AI-enabled Safari browser alongside new operating systems
Can Safari finally get an overflow menu for extension buttons?Apple seems to do a lot of chasing of the latest thing but a lot of core features go unchanged for years to decades
-
System Settings getting shuffled again in macOS 15, among other UI tweaks
Can't say their attempts to redesign settings have gone too well, and the care for HDI at Apple seems to have gone away with the new generation. I hope they get it right this time, but I doubt they'll go back to the old one.

-
New M4 Mac models being tested ahead of likely October release
Wait wait wait, does this report say that it's not just moving the base from 8GB to 12GB as speculated, but the entry level is now 16GB? That's great news if that's what it's saying! Hope there aren't 8GB entry-er models hiding out there
8 core M4 instead of the already binned iPad Pro's 9 core is slightly odd, but it's 4+4 instead of 3+6 so probably makes sense from an available power and thermal situation
